













 Новый эксперимент приближает время, когда парализованные люди смогут полноценно общаться при помощи декодируемой мысленной речи. Возможно, развиваемый метод также пригодится для налаживания связи с пациентами, находящимися в коме или состоянии минимального сознания. Пока, правда, технология сырая и делает первые шаги.
Новый эксперимент приближает время, когда парализованные люди смогут полноценно общаться при помощи декодируемой мысленной речи. Возможно, развиваемый метод также пригодится для налаживания связи с пациентами, находящимися в коме или состоянии минимального сознания. Пока, правда, технология сырая и делает первые шаги.
Брайан Пэйсли (Brian Pasley), Роберт Найт (Robert Knight) и их коллеги из Калифорнийского университета в Беркли воспользовались помощью 15 пациентов, которым делали операции на мозге в связи с опухолью или эпилепсией.
Этим добровольцам вживили 256 электродов в верхнюю (STG) и среднюю (MTG) височные извилины, где находятся зоны, отвечающие за восприятие звуков, в том числе – понимание речи.
Учёные решили прояснить, как реагируют клетки в этих областях, когда человек слышит слова. А дальше авторы работы составили программу, способную синтезировать звуки по картине активности коры.
Общий подход, применённый калифорнийской командой, был идентичен тому, что использовался в опыте с чтением из мозга зрительных образов.
Сначала испытуемые прослушивали по 5-10 минут разговоров, а в это время компьютер записывал сигналы с электродов. Затем, после наработки обширной библиотеки соответствий, исследователи создали две пробные модели, способные реконструировать звуки, которые слышит пациент, по одной лишь активности нейронов.
При этом учёные выявили в картине отклика клеток реакцию на узкие полосы звуковых частот. Потому программа не узнавала отдельные шаблонные слова путём простого сравнения, но спускалась на уровень глубже – она восстанавливала спектрограмму слов. И важно, что это могли быть слова, ранее не использованные в эксперименте.
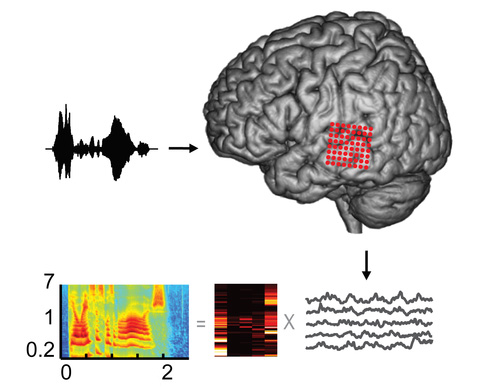 Схема эксперимента. Электроды на поверхности коры (красные точки справа) записывают сигнал от нейронов в то время, когда человек слушает речь в динамиках (образец слева). Изменение потенциала во времени (внизу справа) накладывается на модель реконструкции звука (внизу в центре).
Схема эксперимента. Электроды на поверхности коры (красные точки справа) записывают сигнал от нейронов в то время, когда человек слушает речь в динамиках (образец слева). Изменение потенциала во времени (внизу справа) накладывается на модель реконструкции звука (внизу в центре).
В результате компьютер выдаёт восстановленную спектрограмму (внизу слева). Она показывает распределение мощности акустического сигнала (отражено цветом на диаграмме) в зависимости от частоты (шкала по вертикали, кГц) и времени (по горизонтали, секунды) (иллюстрация Brian N. Pasley et al./ PLoS Biology).
Оказалось, что машина позволяет восстанавливать произвольное слово с приемлемой степенью похожести (что оценивалась и на слух) после всего одного предъявления этого слова испытуемому.
(Подробности эксперимента можно найти в статье в PLoS Biology.)
«У этой работы двухсторонний характер. — заявил Найт. – Это фундаментальная наука, понимание того, как работает мозг. А цель – протезы для людей с нарушениями речи. Аппарат воспроизводил бы то, что они не могут произнести, но могут представить, что они хотят сказать».
Пэйсли пояснил идею: «Существует ряд доказательств, что при прослушивании звука и воображении звука активируются аналогичные области головного мозга. Если вы можете понять отношения между мозговой записью и звуками, вы способны либо синтезировать звук, о котором человек думает, либо просто написать слова».
Брайан сравнил данную технику со способностями профессионального пианиста, который может просто смотреть на клавиши под пальцами другого музыканта, находящегося в звуконепроницаемой комнате, и «слышать» музыку.
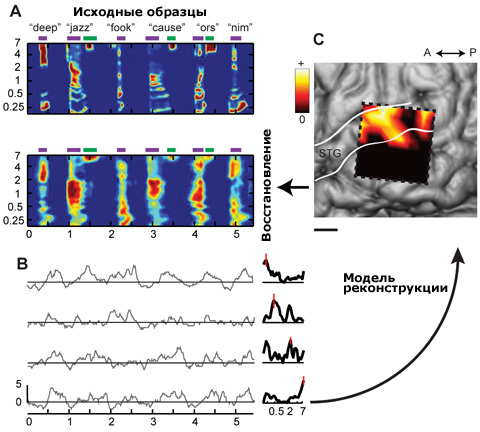 А) Шесть слов для примера. Вверху — исходные спектрограммы, внизу – реконструированные. Шкалы: килогерцы по вертикали, секунды по горизонтали. B) Отклик нейронов на один из звуковых образцов. C) Распределение веса сигналов от разных групп клеток (цветная шкала) в модели реконструкции звука. Пунктирный прямоугольник – область с задействованными в опыте электродами. Масштабная линейка – 1 см (иллюстрация Brian N. Pasley et al./ PLoS Biology).
А) Шесть слов для примера. Вверху — исходные спектрограммы, внизу – реконструированные. Шкалы: килогерцы по вертикали, секунды по горизонтали. B) Отклик нейронов на один из звуковых образцов. C) Распределение веса сигналов от разных групп клеток (цветная шкала) в модели реконструкции звука. Пунктирный прямоугольник – область с задействованными в опыте электродами. Масштабная линейка – 1 см (иллюстрация Brian N. Pasley et al./ PLoS Biology).
Распознавание нескольких слов тоже достигнуто. Но словарный запас той программы невелик, да и точность работы невысока.
Источник: Membrana


